Linux系统下查看动态库依赖关系指令(ldd)
Linux系统下查看动态库依赖关系指令(ldd)
LDD用来打印或者查看程序运行所需的共享库,常用来解决程序因缺少某个库文件而不能运行的一些问题。ldd不是一个可执行程序,而只是一个shell脚本。使用ldd可以很方便的查看库与库之间的依赖关系,存放路径等等;对于排查链接不到库的问题很有帮助;
1、ldd命令全称
ldd命令全称为list dynamic dependencies(列出动态依赖),是Linux下常用的命令之一。它可以用来显示一个可执行文件或者共享库(动态链接库)所依赖的共享库。
2、ldd参数说明
–help 获取指令帮助信息;
–version 打印指令版本号;
-d,–data-relocs 执行重定位和报告任何丢失的对象;
-r, –function-relocs 执行数据对象和函数的重定位,并且报告任何丢失的对象和函数;
-u, –unused 打印未使用的直接依赖;
-v, –verbose 详细信息模式,打印所有相关信息;
3、简单示例
1 | ldd libffi.so.7 |
可以看到,libffi.so.7库需要依赖libc.so.6,而libc.so.6的位置在/lib/aarch64-linux-gnu/libc.so.6 ,它的开始位置是0x0000ffff9ee7a000
4、查看缺少的依赖库
如果当前的动态库因为缺少依赖库而无法链接,那么可以通过ldd查看缺少的依赖库。
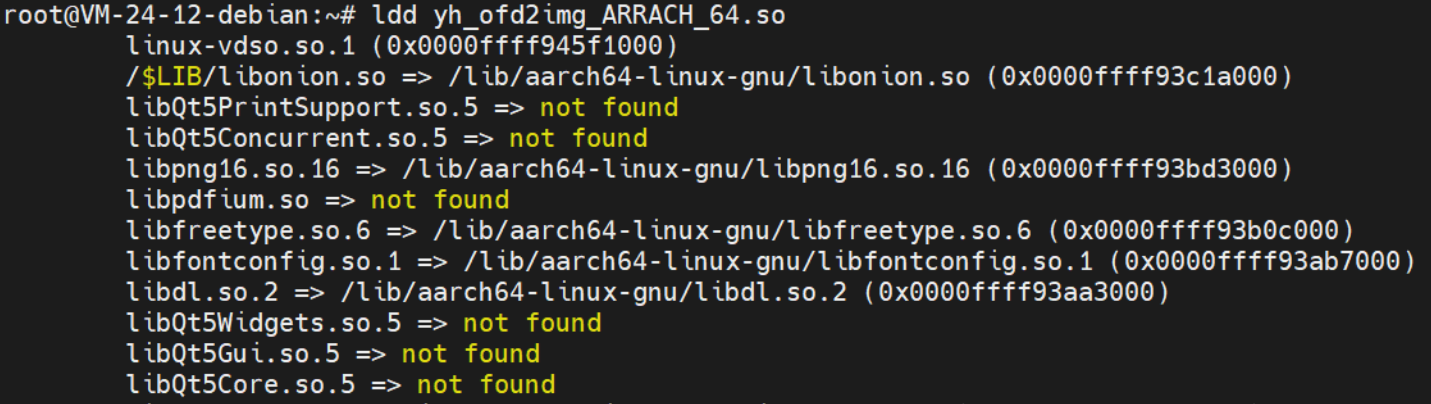
结果中可以看出,yh_ofd2img_ARRACH_64.so库需要依赖libQt5PrintSupport.so.5,而yh_ofd2img_ARRACH_64.so却找不到,方便排查。